

Table of Contents

Entity matching isn’t for the faint of heart. From cleaning & prepping data to matching semi-structured and unstructured text, it is a lot of grunt work that keeps analysts awake at night, knee-deep in complex scripts and piles of digital files!
But what if we told you, there is a faster and better way than relying on spreadsheet formulas and buggy Python scripts to clean, match, and entity resolve your data? What if you could use an on-premises data matching tool to safely, securely, and effortlessly clean, deduplicate, and create master records without having to use any coding skill?
Intrigued?
Read on.
In this article, we’ll demonstrate with a case study how to use WinPure to resolve complex entities & consolidate records for entity resolution without requiring additional training or specialization.
P.S: Talk to us if you need to resolve more than 10M records.
Let’s roll.
Solving the entity resolution problem with codeless data matching
As fancy as entity resolution sounds, it is a necessary evil. Chuckle all you may! But with the type of data we work with, it is impossible to run successful marketing campaigns or make business decisions if it’s not ‘sorted’. For instance, in the image below, Danny Gnomez has three varying records in the CRM, billing software, and a third-party tool.

This disparity in data causes significant challenges in downstream applications, especially when you need to build forecast reports and create predictive analysis algorithms. It doesn’t end there.
The business implications for not entity resolving your data are real – from losing ROI to customer trust, from violating compliance rules to causing data privacy breaches; you’re in for a tough time if your data is not reliable or ‘resolved.’ Entity resolution is critical for companies that want to improve data quality & achieve business goals such as better customer insights, a more efficient operational process, and marketing campaigns built on reliable customer insights. Here’s a quick overview of some key benefits of entity resolution. 👇🏼

So if entity resolution is so important, why are businesses still struggling?
Because nearly 90% of businesses are manually fixing and resolving their entity data, using spreadsheets & scripts; causing excessive operational delays and inefficiencies. Despite spending months of effort, data teams are not able to meet their entity resolution goals (improved data, consolidated views, single source of truth) in time, and are struggling with accuracy & efficiency.
Spreadsheets were not designed to handle complex data management processes – and Python while a powerful language – requires specialized training & advanced experience which many companies do not have the capacity for.
The entity resolution problem isn’t just technical – it’s also the lack of resources & awareness of available technologies that can facilitate both business and tech users with unimagined abilities in data management.
That’s where WinPure comes in.
The platform is built on a robust data quality management framework, with an easy-to-use interface designed for both business and tech users to profile, clean, match, and consolidate records within minutes.
Don’t believe us? Watch this quick video to see how you can match columns, set custom match rules, and adjust match thresholds to meet your needs – all without a single line of code.
How effective is no-code data matching for entity resolution?
If you ask our customers, they’ll gladly tell you, it’s the best decision they’ve ever made to switch from traditional data matching to codeless data matching for their ER goals. Many of them have even integrated our API into their data quality processes to automate the matching process.
A few numbers to indicate effectiveness:
- 90% reduced manual effort. No more manually extracting files for data transformation.
- 97% match accuracy. No more dealing with high levels of false positives.
- 40% improved efficiency (data based on conversations with satisfied customers).
- 60% reduction in operational costs. A customer saved nearly $100K in hiring costs when they used the solution to clean and match data.
The benefits of codeless data matching far outweigh traditional methods. If you’re not going no-code now, you’ll struggle to make sense of the ‘data deluge.’
Example: A retailer uses data matching on an entity resolution dataset
P.S names have been changed to maintain confidentiality.
RetailCo is a mid-sized retail company operating both online and offline. The company sells a wide range of products, including clothing, electronics, and home goods. RetailCo has accumulated vast amounts of customer data from various touchpoints, including in-store purchases, online transactions, loyalty programs, customer service interactions, and social media engagements. However, this data is siloed and often contains duplicate and inconsistent information about the same customers. RetailCo sought our help because it was getting very difficult for their marketing teams to get a comprehensive view of customer behavior and preferences. They were not able to connect the dots between different entities and ended up spending much more time on data prep instead of creating a usable entity resolution dataset.
The team used the trial version to assess the tool’s capabilities and were surprised at how efficiently they were able to clean 2400 records without having to stress about codes or formulas. Using their sample test data, they were able to assess multiple customization features. Here’s a preview of what their data looked like and what they were able to achieve after using the free version of WinPure. 👇🏼

Satisfied with the trial, RetailCo signed up for the annual subscription and has integrated WinPure into their CRM data quality process, enabling faster resolution of noisy and duplicate data.
Here’s how their team used the solution to achieve their entity resolution goals.
A step-by-step process for resolving entities
The matching process for entity resolution is a complex undertaking that involves identifying and comparing entities, often across different data sources. WinPure reduces the manual effort by nearly 80% with easy options for critical tasks like data integration, data profiling, data cleansing, and matching.

✅ Step 1 – integrating or importing data: The more easily you can connect multiple data sources, the more efficient your entity resolution process. WinPure allows native integration to multiple types of database sources, file formats, and CRMs. We also offer customers bespoke integration services where they can request for specific data connectors based on their data requirements. In the case of RetailCo, they were able to integrate Salesforce data directly into the WinPure CRM.

✅ Step 2 – profiling the data for errors: Noisy data ruins entity resolution efforts. Before running the data through a data match solution, it’s always a best practice to ‘clean’ the data. WinPure has over 30 ‘checks’ that alert you on the most common data quality issue affecting your data. With the profiling feature, RetailCo was able to get an in-depth analysis of their data health along a detailed breakdown on some of the critical data quality challenges.

✅ Step 3 – cleaning & standardizing data: With WinPure’s one-click feature, you can clean, normalize, and transform data without losing your original data source. With over 30 built-in powerful cleansing options, RetailCo was able to clean multiple data attributes (information about entities such as their phone numbers, email addresses etc), in one go.

✅ Step 4 – advanced data matching: Alright, we’re at the good part here! WinPure has three types of matching options – exact, numeric, and fuzzy. We helped RetailCo resolve name duplicates with fuzzy matching where the team was able to set and control the match thresholds. Simultaneously, they were also able to resolve phone number and postal data duplicates using the numeric and exact match options. With three powerful options, the team was able to find 300 duplicates in a data set of 2400 records! Additionally, they were also able to use the Knowledge Base Library to build a custom dictionary of their data set. The KBL is one of WinPure’s most powerful features allowing a customization of data-matching capabilities unlike any other software.
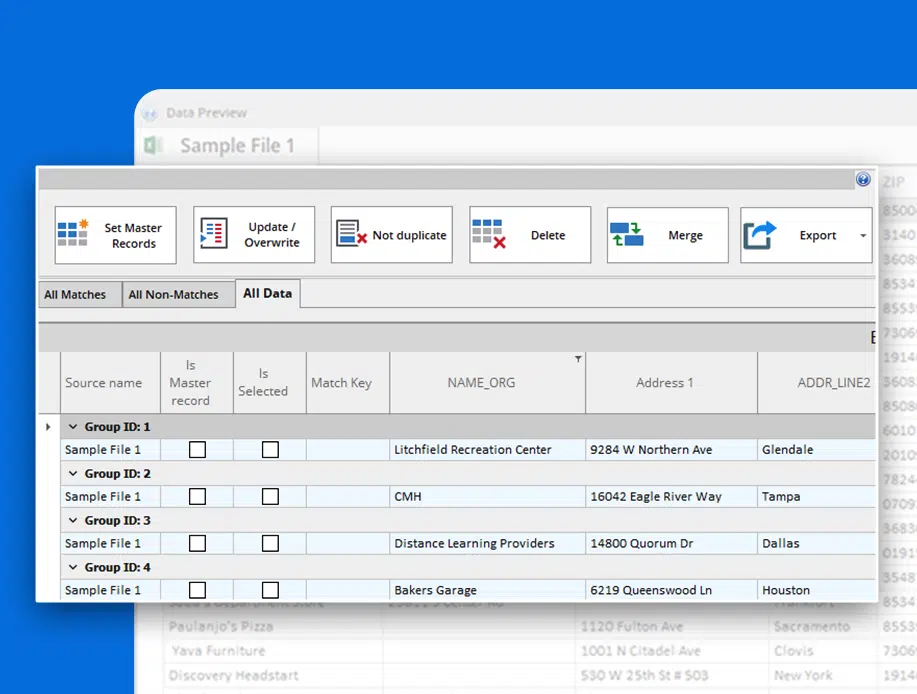 Duplicate data is matched into groups so the user can get a consolidated view of all matches. The RetailCo team decided to overwrite and update their duplicate records on the WinPure platform, without disturbing their original data source.
Duplicate data is matched into groups so the user can get a consolidated view of all matches. The RetailCo team decided to overwrite and update their duplicate records on the WinPure platform, without disturbing their original data source.
Additionally, these records can then be merged or purged and exported directly into your preferred data source.
✅ Step 5 – exporting final master records: Before exporting the final data, the team manually reviewed the results and marked which of the duplicate records they wanted to keep as a master record. They made a new file that held the final master record of all other records. This last step completes the entity resolution process. RetailCo also went a step further by cross-matching this new master record with an international vendor list, to ensure they met compliance regulations. For organizations dealing in international trade, entity resolution is critical to ensure sanctions list compliance.
✅ Step 6 – resolving false positives and false negatives: A false negative occurs when two records should be matched, but the algorithm fails to match them correctly due to a mismatch in attribute values (for e.g failing to flag Mary Smith and Marie Smith as one person). A false positive occurs when the algorithm believes two records belong to the same person but they are not (for e.g John Smith and Jon Smith are two different records). For example, if two records have different names (e.g. “John Smith” and “Jonathan Smith”), an algorithm may not be able to match them even though they are the same person.
With WinPure, the occurrence of false positives is significantly reduced because the user controls the match threshold – which can be compared to an adjustment bar for matching records. The higher the threshold, the closer you get to running an exact match which leads to false negatives (95% and above causes the algorithm to look for nearly exact matches), and the lower the threshold, the higher the chances of a false positives (lower than 90% causes the algorithm to consider distantly similar records as a match). Using WinPure, RetailCo had 80% lower false positive rates than when they were doing data matching manually.
Benefits of using WinPure data matching over traditional methods
Unlike traditional methods that often rely on manual intervention and simplistic rule-based approaches, WinPure leverages advanced algorithms and machine learning techniques to deliver superior matching accuracy. Using the automated data matching capabilities of WinPure, you can achieve entity resolution goals 10x times faster than traditional methods.
Other than speed, some key benefits include:
- 97% match accuracy: WinPure’s advanced algorithms and machine learning techniques enhance matching precision, significantly reducing false positives and negatives compared to traditional rule-based methods.
- Plug-and-play interface: The solution offers an intuitive and easy-to-use interface, allowing users with minimal technical expertise to perform complex data-matching tasks efficiently.
- Advanced data cleansing: It integrates robust data cleansing features, ensuring that data is standardized and deduplicated before matching, enabling companies to clean bulk data in just minutes.
- Scalability and flexibility: WinPure supports various data sources and formats, making it adaptable to different organizational needs and scalable as data volumes grow, unlike many traditional methods that may struggle with diverse and large datasets.
- World-class support team: A quick G2 or Gartner review of WinPure will show you the level of support we offer customers. We are known to deliver on customer feedback, create bespoke solutions, and assist them at every step of the way so they can accomplish their data quality goals faster.
But most importantly – WinPure helps you cut down on resource costs – no more having to hire expensive data scientists or outsourcing the entity resolution job. You can now manage all your data quality and entity resolution challenges in-house with nothing but your data source, your current team, and the WinPure data quality management software powered with entity resolution capabilities.
Ready to entity resolve your data?
There is no better time than now to fix your entity resolution challenges. Get in touch with our team to book personalized data using your sample data and we’ll show you how you can use our advanced data match solution to achieve your entity resolution goals.
Author

Start Your 30-Day Trial!
Secure desktop tool.
No credit card required.
- Match & deduplicate records
- Clean and standardize data
- Use Entity AI deduplication
- View data patterns
... and much more!




