

Best-in-Class Data Deduplication Software
Remove duplicates, consolidate records, and achieve a single source of truth—effortlessly and within minutes.
✅ Advanced deduplication powered by AI & fuzzy logic
✅ Match across multiple datasets at a time
✅ Dedupe names, numbers, & address data






What is data deduplication?
Data deduplication is the process of identifying and resolving duplicate records within a dataset—typically caused by human error, inconsistent data entry, and system imports. It’s a critical function for eliminating redundant entries in CRMs, marketing lists, databases, and spreadsheets, ensuring cleaner, more reliable data across the board.

How Does WinPure’s Data Deduplication Software Work?
WinPure simplifies data deduplication with a visual, rule-based platform to identify near-duplicate records – using proprietary fuzzy match algorithms and AI data matching algorithms. It allows users to easily dedupe contact lists, customer records, government records, cross-jurisdiction records, or multi-source databases. With WinPure, you can deduplicate at scale with unmatched performance & accuracy.
✅ Flexible Matching Across Multiple Fields
Detect duplicates based on full name, email, address, or any combination of fields using both exact and fuzzy match logic.
✅ Secure On-Premises Dedupe Tool
WinPure runs on your local environment, giving you full control over data privacy, compliance, and performance.
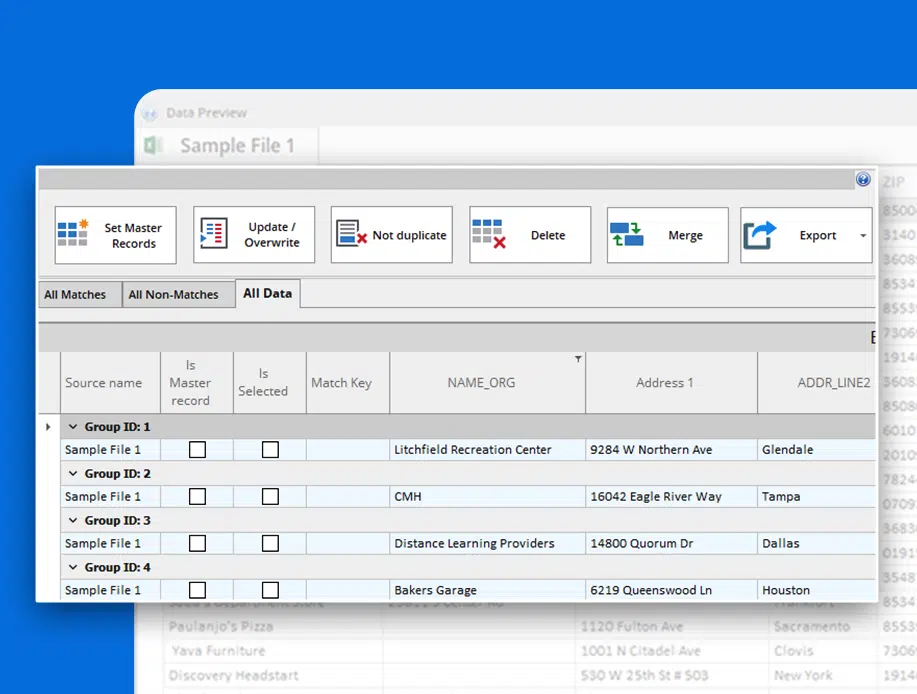
✅ Visual View of Duplicate Matches
See duplicates side by side with field-level match scores and color-coded indicators. Easily merge, purge, or delete records from the interface.
WinPure’s Data Dedupe Software:
Solve Complex Duplicates in Just Three Steps!
Connect, Profile, & Prepare the Data
Start with seamless data integration and intelligent profiling to uncover hidden quality issues that could affect deduplication accuracy. WinPure connects to any system, evaluates your data across 30+ checkpoints, and flags potential errors before processing begins.
✅ Connect to databases, CRMs, and spreadsheets with no data reshaping
✅ Profile fields for inconsistencies, anomalies, and invalid formats
✅ Get an overview of critical data quality issues affecting the dataset


Clean and Standardize for Smarter Matching
Enhance match accuracy with one-click cleansing and custom standardization rules. Winpure’s CleanMatrixTM and Word Manager lets you normalize formats and remove noise like suffixes or abbreviations so the match engine can focus on what matters.
✅ Standardize names, emails, phone numbers, and address formats
✅ Use Word Manager to treat terms like “Ltd” and “Limited” as equal
✅ Clean entire columns or targeted fields before matching begins
Match, Review & Merge with Confidence
Run fuzzy and AI-powered match logic to detect duplicates – even without exact identifiers – then use the AI data match to perform complex entity resolution. Choose to merge, purge, or generate a master record, all with detailed scoring and manual review options.
✅ Apply field-specific fuzzy logic and adjustable thresholds
✅ Review duplicate matches visually with match confidence scores
✅ Merge records automatically or manually based on defined rules
CASE STUDY:
Easy duplicate record management with intuitive data matching
Brotherhood Mutual, an insurance organization needed an intuitive data dedupe software that was powerful yet easy enough for their business teams to use. WinPure stood out as the ideal solution, offering a user-friendly interface that allowed both technical and non-technical teams to efficiently manage duplicate records.
Within weeks of implementation, the marketing team successfully resolved duplicate customer records, leading to streamlined operations, improved efficiency, and more accurate customer data—ultimately driving better business outcomes.

Why Teams Choose WinPure for Data Deduplication

High Accuracy Deduplication at Scale
Handle millions of records with advanced match logic that adapts to your data.

Full Control Over Deduplication Rules
Customize how duplicates are defined, scored, and resolved.

Reusable Match Projects
Save and reuse your deduplication rules to streamline future data cleansing tasks.

Scalable Across Teams & Datasets
Deduplicate large datasets across departments, systems, or file types.

Preserve Data Integrity
Non-destructive deduplication ensures original data remains auditable.

Dedicated Expert Support
Get help configuring match rules, thresholds, and reviewing complex scenarios.
Working with Industries:
Deduplication for Business-Critical Projects

Healthcare & Life Sciences
Eliminate duplicate patient profiles across EMRs for cleaner care coordination and billing.

Financial Services
Detect and merge duplicate client accounts for better compliance and customer visibility.

Retail & E-Commerce
Remove redundant customer and transaction data to streamline marketing and operations

Manufacturing & Supply Chain
Standardize and deduplicate vendor, SKU, and logistics data across systems.

Government & Public Sector
Resolve duplicate citizen records for accurate public service delivery.

Non-Profit & Education
Clean donor and student databases to improve reporting and engagement outcomes.
Recommended by industry leaders
Rated by leading platforms

Definitely recommend WinPure for anyone dealing with large quantities of data. The fuzzy matching is really intuitive and after a bit of testing with the settings it ends up being able to remove dupes better than anything else I've ever tried.

Using WinPure shaves hours off when comparing data from different sources. Its very fast and the results are brilliant. The product support and ease of use are great. The support team is very knowledgeable and easy to connect with.

We perform multiple matching projects for our clients and WinPure has filled the bill for these. The product is very easy to use, incredibly fast and we can complete a large matches in a very short time.

WinPure is a really great product, we've been using it with excellent results for many years now, for finding and removing duplicate records and to keep our lists and database more accurate.

WinPure Clean & Match Enterprise works really great to analyze data and find duplicated customer records. It saves us tons of money when mailing catalogs. This is a great product for the money and easy to use.

A very powerful but easy to use tool for cleansing and removing duplicates from databases. I have used Clean & Match for many of my clients, and I am regularly recommending this product to other companies.




Start Your 30-Day Trial!
Secure desktop tool.
No credit card required.
- Match & deduplicate records
- Clean and standardize data
- Use Entity AI deduplication
- View data patterns
…. and much more!
Data quality management resources & insights

Meet Data Leaders & Experts
Got a question for top data professionals? Our webinars provide a unique opportunity to meet and engage with industry people as they answer your queries live.

Listen to Insightful Podcasts
Tune in to listen to the people who know their way around data. Podcasts are presented by the WinPure team, bringing you insights to make data-driven decisions.

Enjoy Interviews and Insights
Read exclusive interviews, helpful guides, and insights from top data management experts. We help you make sense of your data with a knowledge hub of quality content.
WinPure Data Deduplication FAQs
WinPure offers a faster, more user-friendly alternative to SQL queries and Python scripts for duplicate data removal. Unlike code-based approaches, it provides an intuitive, no-code interface, allowing both technical and non-technical users to identify, merge, and cleanse duplicate records effortlessly. With pre-built fuzzy matching, AI-driven entity resolution, and automation features, WinPure eliminates the need for complex scripting, manual tuning, and debugging while offering seamless integration with databases, CRMs, and spreadsheets.
WinPure uses a combination of fuzzy matching, deterministic algorithms, and AI-powered entity resolution to detect exact and near-duplicate records, even when data contains misspellings, formatting inconsistencies, or missing fields.
WinPure provides confidence scoring, customizable match thresholds, and an interactive review panel, giving users full control over merging, purging, or keeping specific records to maintain data integrity and accuracy.
Yes! WinPure is built to handle millions of records with high-speed processing, offering batch processing, automation, and on-premise deployment options for enterprises that require secure, large-scale data deduplication.
Yes! WinPure supports address data deduplication by identifying and resolving duplicate, incomplete, or inconsistent address entries across datasets. It applies fuzzy matching, phonetic analysis, and normalization rules to detect variations in street names, abbreviations, postal codes, and formatting differences. Users can also verify and validate location data of over 250+ countries against official databases.