

Table of Contents

Esta guía de coincidencia difusa de datos está diseñada para equipos de negocio y tecnología que trabajan directamente con datos de clientes y que a menudo se enfrentan a las complejidades de nombres, fechas, números de teléfono, direcciones de correo electrónico y datos de ubicación. La guía ayudará a responder algunas preguntas sobre la coincidencia de datos y permitirá a los equipos identificar nuevos prospectos, resolver identidades duplicadas y crear listas de clientes limpias utilizando técnicas de coincidencia difusa.
Listos.
¡Vamos allá!
Entendiendo los desafíos con los datos de clientes
Para comprender la necesidad e importancia de los procesos de coincidencia difusa, primero debemos abordar los desafíos con los datos de clientes, específicamente los datos de contacto como nombres, números de teléfono, direcciones de correo electrónico y datos de ubicación, que suelen venir acompañados de problemas como entradas duplicadas, valores faltantes, atributos cuestionables, información falsa y múltiples variaciones.
La imagen a continuación es un ejemplo. Tienes diferentes versiones de un Mike Johnson cuyas direcciones y números de teléfono están lejos de ser precisos. En el CRM de la empresa se le conoce como Mike, pero el equipo de facturación lo identifica como Michael, mientras que en la base de datos de proveedores figura como M. Johnson. ¿Cuál de estas identidades es real, completa y precisa? Responder a esta simple pregunta requeriría que los equipos de negocio y tecnología pasaran incontables horas perfilando y revisando los datos en múltiples hojas de cálculo.
Por lo tanto, la coincidencia difusa de datos no es simplemente una tecnología de TI sofisticada, sino que es, en esencia, la forma más efectiva de resolver estas discrepancias e inexactitudes, llegando incluso a unificar estas identidades dispares en un perfil de cliente consolidado para que los equipos de negocio y tecnología trabajen en él.

Además de en marketing y ventas, los datos de clientes también son fundamentales cuando las empresas se fusionan y desean combinar sus sistemas de gestión de relaciones con clientes (CRM). En estos casos, es necesario eliminar duplicados, fusionar registros y depurar entradas redundantes, y tratar de hacer todo esto con el viejo Excel ya no es suficiente. Los equipos necesitan capacidades de coincidencia de datos que les permitan escanear millones de filas, identificar entradas duplicadas y redundantes en minutos, no en días o meses.
Es aquí donde entran en juego las herramientas y tecnologías de coincidencia difusa de datos.
Pero antes de hablar sobre técnicas de implementación de coincidencia difusa, repasemos algunos conceptos básicos.
¿Qué es la coincidencia difusa de datos?

¿Cómo funciona la lógica de coincidencia difusa?
La lógica de coincidencia difusa funciona comparando dos cadenas de texto y revisando la similitud entre ellas. Por ejemplo, comparará Kathryn con Katherine y analizará el nivel de similitud. Luego utilizará un algoritmo para asignar un puntaje de similitud. En este caso, si la lógica de coincidencia utiliza el algoritmo de Levenshtein, el nombre obtiene un puntaje de similitud del 80-85%, lo que indica que es un duplicado.
Otros algoritmos, como Jaro-Winkler, otorgan mayor peso a los caracteres coincidentes al inicio de las cadenas, lo cual es útil para nombres donde las iniciales o prefijos comunes son significativos. Soundex, un algoritmo fonético, es útil al comparar nombres con diferentes ortografías pero sonidos similares, como «Smith» y «Smyth». Basándose en el puntaje de similitud calculado por el algoritmo elegido, la lógica de coincidencia difusa aplica un umbral predefinido (por ejemplo, 85%) para clasificar dos entradas como duplicados si alcanzan o superan este umbral. Esto permite que la coincidencia difusa tenga en cuenta pequeños errores, variaciones y ortografías alternativas en los datos.
¿Cuáles son los algoritmos comunes de coincidencia difusa?
La implementación de la coincidencia difusa de datos puede realizarse de tres maneras principales: implementación manual usando Python, tecnología sin código y coincidencia difusa basada en IA/LLM.
- Implementación manual: Requiere codificar directamente los algoritmos utilizando bibliotecas de Python como fuzzywuzzy y Levenshtein, ofreciendo la máxima flexibilidad para tareas complejas.
- Plataformas sin código: Ofrecen interfaces fáciles de usar que permiten a los analistas de negocio realizar coincidencias difusas sin conocimientos de programación.
- Coincidencia difusa basada en IA/LLM: Utiliza modelos preentrenados para comprender el contexto y las similitudes semánticas, mejorando la precisión y eficiencia de la coincidencia de datos a través de API de servicios de IA.
Teoría y algoritmos de coincidencia difusa
- Levenshtein Distance (Distancia de edición): Este algoritmo mide la similitud entre dos cadenas contando el número mínimo de ediciones de un solo carácter (inserciones, eliminaciones o sustituciones) necesarias para convertir una palabra en otra.
Es altamente efectivo para identificar errores tipográficos y pequeñas variaciones. Por ejemplo, convertir «cat» en «cot» requiere una sustitución, dando una distancia de Levenshtein de 1. Es particularmente útil en aplicaciones donde los errores o variaciones menores son comunes, como errores de entrada en nombres o direcciones. - Jaro-Winkler Distance: Este algoritmo extiende la métrica de distancia Jaro al otorgar calificaciones más favorables a las cadenas que coinciden desde el principio. Calcula la similitud en función del número y orden de caracteres coincidentes.
La variante Jaro-Winkler agrega una escala de prefijos, mejorando la puntuación para cadenas con caracteres iniciales coincidentes. Por ejemplo, «John» y «Jon» reciben una puntuación más alta que «John» y «Jane» debido a que comparten caracteres iniciales. Es especialmente útil para coincidir nombres personales, donde los prefijos comunes y las iniciales son indicadores significativos de similitud. - Soundex: Diseñado para manejar coincidencias fonéticas, este algoritmo convierte palabras en un código basado en sus sonidos. Es particularmente útil para comparar nombres con diferentes ortografías pero pronunciaciones similares, como «Smith» y «Smyth».Soundex asigna un código de cuatro caracteres a cada nombre, donde el primer carácter es la letra inicial del nombre, y los tres caracteres siguientes representan los sonidos consonantes principales. Este enfoque permite una coincidencia efectiva de nombres fonéticamente similares pero ortográficamente diferentes, siendo ideal para investigaciones genealógicas y coincidencias de datos históricos.
¿Por qué se necesita la coincidencia difusa para mejorar la calidad de los datos?
Los datos de los clientes están compuestos esencialmente por cinco componentes: nombres, fechas, números de teléfono, direcciones de correo electrónico y datos de ubicación.
Cuando las empresas no establecen parámetros de calidad de datos, terminan con información sucia, duplicada e inexacta. Por ejemplo, puedes encontrar «New York» listado como NY, NYC o N.York en toda la base de datos. Cuando estos datos se integran en un CRM o se usan en una aplicación descendente, las variaciones pueden causar errores de mapeo. Peor aún, puede generar datos desordenados y difíciles de manejar.
La coincidencia difusa puede usarse para abordar estos desafíos de calidad de datos, permitiendo que los equipos trabajen con conjuntos de datos consolidados. Algunos problemas clave de calidad de datos que puedes resolver con una herramienta robusta de coincidencia difusa incluyen:

✅Datos Duplicados:
Los registros duplicados ocurren cuando varias entradas representan a la misma entidad. La coincidencia difusa de datos consolida entradas como “Robert Brown,” “Bob Brown,” y “R. Brown” en un único registro preciso.
Resolviendo desafíos de datos de contacto con técnicas de coincidencia difusa
Los datos de clientes están compuestos por múltiples elementos que, cuando se gestionan con precisión, proporcionan una imagen completa de cada individuo. A nivel de base de datos, estos elementos se pueden reducir a nombres, números de teléfono, fechas, direcciones de correo electrónico y datos de ubicación. En conjunto, estos componentes forman la «información de contacto» de un individuo y a menudo se utilizan en procesos de coincidencia de datos para identificar duplicados. Entre ellos, los números de teléfono y las fechas de nacimiento suelen usarse como identificadores únicos, valores que son exclusivos de cada individuo.
Cada componente presenta desafíos únicos: los identificadores personales suelen tener variaciones o errores tipográficos, la información de contacto puede quedar desactualizada o estar mal formateada, y los datos transaccionales y de comportamiento pueden estar dispersos en diferentes plataformas. Una gestión de datos eficaz requiere abordar estos desafíos para mantener una visión unificada y precisa del cliente, y ahí es donde la coincidencia difusa de datos resulta ser una técnica útil.
Datos de nombres y los desafíos de la coincidencia difusa de nombres
Los nombres son complicados. Puede llevarte un tiempo descubrir si Kathryn, Katherine, Kathy, Cathy, Catherine, Kath, Cath (¡Uff!) son la misma persona o duplicados.
El corrector ortográfico no ayuda. Las personas usan cualquier variación de sus nombres que deseen en cualquier plataforma. Katherine puede aparecer como Kath C en Facebook, pero como Kathryn en LinkedIn. Si intentaras manejar estas variaciones en una hoja de Excel, te tomaría siglos.
¿Pero por qué es tan difícil? Vamos a descubrirlo.
La Anatomía de un Nombre
En una base de datos, los nombres suelen ser los primeros componentes utilizados para comparar y coincidir identidades, y también son los más complejos.
No solo tienes que coincidir nombres y apellidos, sino también sufijos y títulos honoríficos. Si eso no es suficiente, también enfrentamos la variabilidad de los nombres culturales y sus versiones.
Además, podrías lidiar con fraude de identidad, una situación en la que un individuo falsifica su nombre y datos, causando un riesgo de seguridad. Los datos fraudulentos son un desafío complejo que enfrentan bancos, gobiernos y organizaciones financieras, y casi siempre comienza con un nombre.
Aparte de los nombres individuales, también están los nombres de empresas o corporaciones que pueden incluir números y abreviaturas, como IBM (abreviatura) o 7Eleven (con un número en el nombre).
Cuando estas identidades están duplicadas o no estandarizadas, se vuelven difíciles de resolver, especialmente si la empresa no tiene una herramienta de coincidencia de nombres.
La coincidencia difusa de nombres permite a un analista determinar si la Sra. Katherine Jones de NYC es la misma persona que la Sra. Catherine de NY, incluso si tienen números de teléfono o direcciones de correo electrónico diferentes.
Desafíos adicionales con datos de nombres que la coincidencia difusa puede resolver:
- Puntuaciones en nombres: Ejemplo: J.K. Rowling, C.S. Lewis
- Sufijos: John Doe Jr., Dra. Jane Smith, Jane Smith Ph.D
- Nombres de empresas: Alphabet, Google LLC, AT&T (American Telephone & Telegraph)
- Nombres multiculturales: María, José, Rodríguez
- Homónimos: Wright/Rite
Soluciones de coincidencia difusa de nombres pueden ayudar a:
- Identificar duplicados en nombres multiculturales
- Detectar y corregir nombres faltantes
- Identificar múltiples variaciones del mismo nombre en tu base de datos
- Estandarizar nombres y seguir un diccionario personalizado (¡que puedes crear!)
- Fusionar todos los posibles duplicados en grupos para su revisión
Mucho puede salir mal con los nombres, incluso si tienes un sistema bien definido y un esquema de datos sólido, ya que los nombres son inherentemente complejos, y más aún cuando hay errores de entrada de datos o las personas usan múltiples variaciones de sus nombres en diferentes aplicaciones.
Necesitas algo más que una fórmula de Excel para manejar estas variaciones, y ahí es donde la coincidencia difusa de datos resulta ser más útil.
Mira cómo resolver desafíos de coincidencia de nombres con WinPure:
Números de teléfono y coincidencia numérica
Con los SSNs, identificaciones fiscales y números de identificación sensibles restringidos por las leyes de privacidad de datos, los números de teléfono móvil son los únicos identificadores únicos “vivos” públicamente disponibles que se pueden usar. Sin embargo, esto está lejos de ser simple y fácil.
Los números de teléfono también tienen múltiples formatos. Considera lo siguiente:
Los números de teléfono suelen ser desordenados y variados, especialmente cuando se incluyen diferentes formatos e información adicional. Observa estos ejemplos de EE. UU. y el Reino Unido:
Formatos de EE. UU.:
- (800) 555-1234
- +1 (800) 555-1234
- 1-800-555-1234
- 8005551234
- (800) 555-1234 Ext. 67 (manejar extensiones puede ser un desafío: ¿los datos las consideran?)
Formatos del Reino Unido:
- +44 20 7946 0958
- 02079460958
- 020 7946 0958 (nota el espaciado que se agrega frecuentemente en los formatos del Reino Unido para mejorar la legibilidad)
- +44 (0) 20 7946 0958 (algunos formatos del Reino Unido incluyen paréntesis alrededor del cero inicial)
- 020-7946-0958 Tía Jane (el texto libre puede incluir notas, como un nombre de contacto, que técnicamente no forma parte del número de teléfono).
Estos ejemplos muestran la variedad de formatos, extensiones e incluso notas que suelen encontrarse en los campos de números de teléfono, creando un desafío para la consistencia y precisión de los datos.
La coincidencia difusa de datos numéricos puede ayudar a limpiar y unificar estos variados formatos de números de teléfono identificando similitudes entre diferentes representaciones. Por ejemplo, puede reconocer que «(800) 555-1234» y «800-555-1234» se refieren al mismo número a pesar de las diferencias de formato. Los algoritmos utilizados en la coincidencia difusa detectan patrones y estandarizan entradas eliminando espacios, símbolos o extensiones, lo que permite un conjunto de datos limpio y consistente.
Además, herramientas como WinPure permiten estandarizar los datos telefónicos, asegurando que cumplan con un formato específico. También se pueden eliminar puntuaciones accidentales o transposiciones en los datos.
Fechas y el desafío de los formatos
El principal problema con las fechas son los formatos. Algunos ejemplos comunes incluyen:
- MM/DD/AAAA – Usado principalmente en Estados Unidos, ej., 12/31/2023.
- DD/MM/AAAA – Común en el Reino Unido y muchos otros países, ej., 31/12/2023.
- AAAA-MM-DD – Un estándar internacional (ISO 8601), usado en áreas técnicas, ej., 2023-12-31.
- Mes DD, AAAA – Popular en contextos formales, especialmente en EE. UU., ej., December 31, 2023.
- DD Mes AAAA – Común en Europa, ej., 31 December 2023.
- DD.MM.AAAA – Frecuente en partes de Europa, ej., 31.12.2023.
Ahora, añadamos otra capa: la hora.
Por ejemplo, si alguien registra una fecha de nacimiento como 1 de abril de 1990 desde la costa oeste de EE. UU. a las 4:45 p. m., el sistema podría grabarla con una marca de tiempo de 4:45 PM PST. Al visualizar esta fecha desde otra región, como al cruzar la línea internacional de cambio de fecha, el sistema podría mostrarla como 2 de abril de 1990. ¿Confuso? ¡Definitivamente!
Los sistemas de coincidencia difusa ayudan al estandarizar formatos de fechas y resolver inconsistencias causadas por zonas horarias. En lugar de depender de coincidencias exactas, pueden reconocer fechas como equivalentes si están dentro de un rango de 24 horas o señalarlas para revisión en caso de discrepancias.
Datos de ubicación y la importancia de la verificación de direcciones
Los datos de dirección o ubicación enfrentan dos desafíos principales: entradas desordenadas o ruidosas y múltiples identidades asociadas a una misma ubicación. Por ejemplo, cinco miembros de una familia comparten la misma dirección, al igual que cinco mil empleados de una organización.
Los errores comunes en los datos de dirección incluyen:
- Nombre de calle y tipo: Una calle puede aparecer como «Main St,» «Main Rd,» «Main Blvd,» etc.
- Códigos postales: En EE. UU., los códigos ZIP incluyen extensiones como «+4» (ej., 12345-6789), que no siempre se utilizan de manera consistente.
- Países: Variaciones como «Estados Unidos,» «USA» o «EE.UU.» pueden causar inconsistencias.
Herramientas como WinPure pueden estandarizar y verificar direcciones contra bases de datos oficiales (por ejemplo, USPS en EE. UU.), asegurando formatos correctos y entradas consistentes.
Direcciones de correo electrónico y registros duplicados
Al igual que los números de teléfono, las direcciones de correo electrónico son únicas para cada individuo; sin embargo, una persona puede tener múltiples direcciones de correo electrónico únicas. Imagina un cliente que tenga un correo personal, uno desechable y uno laboral, todos registrados en tu CRM.
La coincidencia difusa puede ayudar a identificar y consolidar múltiples direcciones de correo electrónico que pertenecen al mismo individuo dentro del CRM. Mediante algoritmos de similitud, la coincidencia difusa puede detectar patrones entre dominios de correo electrónico o nombres asociados con el mismo cliente (por ejemplo, coincidiendo «john.doe@gmail.com,» «j.doe@company.com» y «john_doe@yahoo.com«). También puede considerar ligeras variaciones o errores tipográficos, como “john.doe” frente a “john_doe,” que de otro modo podrían crear registros duplicados.
Una vez identificadas estas entradas similares, la coincidencia difusa permite que el CRM las vincule a un único perfil de cliente. Esto genera una vista unificada del individuo, lo que permite un seguimiento más preciso y mejora la calidad de las interacciones al evitar comunicaciones redundantes a través de múltiples correos electrónicos.
Además de estos componentes básicos de información de contacto, tu CRM también puede contener datos incorrectos o datos provenientes de fuentes externas con información adicional que necesitaría ser coincidente. Estos podrían ser datos numéricos o de texto, como identificadores de proveedores, nombres de productos, descripciones, entre otros. La tecnología de coincidencia difusa de datos es fundamental para reunir y armonizar toda esta información diversa.
Implementación de coincidencia difusa
Existen múltiples formas de implementar la coincidencia difusa de datos. Dependiendo de tu nivel de habilidad y necesidades específicas, puedes elegir entre los siguientes métodos:
SQL
SQL es una herramienta poderosa para implementar la coincidencia difusa de datos, especialmente cuando se trabaja con datos estructurados en bases de datos relacionales.
Mediante funciones de SQL como SOUNDEX, DIFFERENCE y UDFs (Funciones Definidas por el Usuario) para la distancia de Levenshtein, puedes realizar coincidencias difusas directamente dentro de la base de datos. Este enfoque es efectivo para grandes conjuntos de datos, pero requiere un buen conocimiento de SQL y gestión de bases de datos.
Plataformas sin código (No-Code)
Las plataformas sin código ofrecen interfaces fáciles de usar para realizar coincidencias difusas sin necesidad de conocimientos de programación. Herramientas como WinPure brindan funcionalidad de arrastrar y soltar para configurar reglas de coincidencia difusa. Este enfoque es ideal para analistas de negocios y usuarios no técnicos que necesitan gestionar la calidad de los datos sin codificación extensa.
Inteligencia Artificial (IA)
La coincidencia de datos basada en IA utiliza modelos de aprendizaje automático y preentrenados para comprender contextos y similitudes semánticas, mejorando la precisión y la eficiencia en la coincidencia de datos.
Servicios de IA como WinPure’s AI Data Match, Google Cloud’s Dataflow y Microsoft Azure’s Cognitive Services pueden encontrar y vincular registros automáticamente considerando múltiples atributos como nombre, fecha de nacimiento, correo electrónico y dirección.
Este método es capaz de detectar coincidencias complejas que las técnicas tradicionales de coincidencia difusa podrían pasar por alto, proporcionando mayor precisión con menos intervención del usuario.
Coincidencia difusa usando Python y R
Python y R son lenguajes de programación poderosos ampliamente utilizados para la coincidencia de datos, con diversas bibliotecas y paquetes que facilitan esta tarea. Aquí se detalla cómo funcionan y los desafíos asociados con ellos:
Python:
Python es conocido por su flexibilidad y amplio soporte de bibliotecas. Una de las bibliotecas más populares para coincidencia difusa en Python es FuzzyWuzzy, que utiliza el algoritmo de distancia de Levenshtein para calcular similitudes entre cadenas.
- FuzzyWuzzy: Es altamente efectiva para tareas de coincidencia de complejidad simple a moderada. Permite calcular puntuaciones de similitud entre cadenas, identificar coincidencias parciales y ordenar datos según la similitud.
- FuzzyWuzzy utiliza la distancia de Levenshtein, que mide el número mínimo de ediciones de un solo carácter (inserciones, eliminaciones o sustituciones) necesarias para transformar una palabra en otra. Por ejemplo, la distancia entre «kitten» y «sitting» es 3 (k→s, e→i, →g).
- PolyFuzz: Otra biblioteca que permite el uso de múltiples algoritmos de similitud de cadenas y puede personalizarse para tareas de coincidencia más específicas.
- Soporta algoritmos como TF-IDF, similitud coseno y otros, proporcionando flexibilidad para elegir el algoritmo adecuado según el caso de uso.
Usando estas bibliotecas, los desarrolladores pueden escribir scripts para limpiar datos, aplicar algoritmos de coincidencia difusa y extraer coincidencias relevantes. Sin embargo, este proceso consume recursos y requiere un esfuerzo de desarrollo significativo.
R:
R también es un lenguaje popular para análisis de datos y coincidencia, con paquetes especializados como stringdist, fuzzyjoin y RecordLinkage. Aquí se explica cómo estos paquetes contribuyen a la coincidencia difusa:
- stringdist: Este paquete ofrece varios algoritmos de distancia de cadenas, incluidos Levenshtein, Jaro-Winkler y Soundex. Permite calcular matrices de distancia y aplicar estas métricas para identificar cadenas similares. Por ejemplo, la distancia Jaro-Winkler entre «martha» y «marhta» es 0.961.
- fuzzyjoin: Se utiliza para realizar uniones difusas en marcos de datos, permitiendo la combinación de conjuntos de datos basados en coincidencias aproximadas en lugar de exactas.
- RecordLinkage: Se centra en la vinculación y deduplicación de registros, ofreciendo herramientas para comparar registros, calcular puntuaciones de similitud e identificar duplicados en los conjuntos de datos.
Desafíos al usar Python y R para la coincidencia difusa
Usar Python y R para la coincidencia difusa implica varios desafíos que pueden afectar significativamente la eficiencia y productividad.
El primer obstáculo es extraer datos de diversas fuentes, cada una con formatos y estructuras diferentes. Este proceso requiere escribir scripts para conectar con bases de datos, consultar datos y manejar diversos esquemas de datos.
Luego, definir el alcance de la coincidencia es fundamental. Esto implica decidir qué campos se deben coincidir y establecer los umbrales de similitud, lo que requiere un profundo entendimiento de los datos.
Estandarizar los formatos de datos, corregir errores y garantizar la consistencia entre los conjuntos de datos son pasos esenciales para una coincidencia precisa, y estos pasos de preprocesamiento pueden ser muy tediosos.
Probar y ajustar los algoritmos para encontrar el más eficaz para casos de uso específicos es otra tarea meticulosa. Esto incluye realizar múltiples pruebas, comparar resultados y ajustar parámetros para minimizar los falsos positivos y negativos.
Gestionar las discrepancias requiere una mejora continua y validación, que a menudo involucra revisiones manuales basadas en el conocimiento del dominio.
Por último, consolidar los registros coincidentes en registros principales y entregar el conjunto de datos deduplicado al equipo de negocio para su uso en la toma de decisiones y operaciones es un proceso complejo.
Todo este flujo de trabajo, desde la extracción de datos hasta la entrega final, puede llevar meses, exigiendo talento especializado y una considerable inversión de tiempo.
Beneficios de usar soluciones automatizadas de coincidencia difusa de datos sobre Python y SQL
Implementar coincidencia difusa de datos mediante codificación en Python y R ofrece control y flexibilidad, pero conlleva desafíos significativos.
Así es como las soluciones automatizadas pueden facilitar el proceso de coincidencia difusa de datos:
✅ Facilidad de uso:
Sin necesidad de codificación: Las herramientas automatizadas proporcionan interfaces fáciles de usar que permiten a los usuarios de negocios y equipos técnicos realizar coincidencias difusas sin escribir código. Esto reduce la barrera de entrada y permite que un rango más amplio de personal gestione la calidad de los datos. Herramientas como WinPure ofrecen funcionalidad de arrastrar y soltar para configurar reglas de coincidencia difusa, lo que hace que sea sencillo para los usuarios configurar y ejecutar tareas de coincidencia de datos.
✅ Velocidad y eficiencia:
Procesamiento rápido: Las soluciones automatizadas pueden procesar grandes conjuntos de datos rápidamente, realizando operaciones complejas de coincidencia difusa en minutos en lugar de meses.
✅ Precisión y exactitud:
Algoritmos avanzados: Estas herramientas vienen equipadas con algoritmos sofisticados que están afinados para diversas tareas de coincidencia difusa, garantizando alta precisión y reduciendo falsos positivos y negativos.
✅ Escalabilidad:
Manejo de grandes volúmenes de datos: Las soluciones automatizadas están diseñadas para manejar grandes volúmenes de datos, lo que las hace ideales para empresas con conjuntos de datos extensos y complejos.
✅ Reglas de coincidencia personalizables:
Flexibilidad en la configuración: Los usuarios pueden establecer reglas de coincidencia personalizadas según sus necesidades específicas, como coincidir nombres de empresas con datos de direcciones o estandarizar abreviaturas y acrónimos. Por ejemplo, un usuario puede configurar la herramienta para reconocer y estandarizar variaciones de nombres de empresas como «Inc.» y «Incorporated.»
✅ Capacidades de integración:
Integración de datos sin interrupciones: Las soluciones automatizadas pueden conectarse a diversas fuentes de datos, integrando y limpiando datos de diferentes plataformas en un solo conjunto de datos cohesivo.
Guía paso a paso para la coincidencia difusa de datos utilizando WinPure
El software de coincidencia difusa de datos de WinPure ofrece una forma eficiente de limpiar y desduplicar los datos de contacto, ayudándote a mantener registros precisos y consistentes. Con su interfaz fácil de usar, puedes identificar rápidamente los duplicados, combinar entradas similares y mejorar la calidad de los datos sin un esfuerzo manual extenso.
Aquí tienes una guía rápida paso a paso.
✅ Selecciona los archivos: Elige los conjuntos de datos que necesitas limpiar y coincidir. Este paso implica identificar las fuentes de datos que requieren desduplicación o integración. Pueden ser listas de clientes, bases de datos de CRM, listas de marketing o cualquier otro archivo de datos que contenga entradas potencialmente redundantes o inconsistentes.

✅Limpiar los datos: Estandariza el formato, corrige errores tipográficos y asegúrate de que los datos estén actualizados. Limpiar los datos es crucial, ya que prepara los conjuntos de datos para una coincidencia efectiva. Esto incluye corregir errores ortográficos, estandarizar los formatos de direcciones y garantizar que todas las entradas sigan una estructura consistente.
✅ Coincidencia entre archivos: Realiza la coincidencia dentro de un solo archivo o entre dos archivos diferentes. Este paso identifica posibles duplicados e inconsistencias dentro de los conjuntos de datos seleccionados. Por ejemplo, realizar una coincidencia de una lista de clientes contra una base de datos de marketing para identificar registros superpuestos.

✅ Establecer reglas de coincidencia: Define los criterios para la coincidencia, como hacer coincidir los nombres de las empresas con los datos de la dirección para identificar duplicados. Las reglas de coincidencia ayudan a especificar los atributos que deben compararse. Por ejemplo, hacer coincidir basándose tanto en el nombre como en la dirección puede ayudar a garantizar que diferentes entradas para el mismo cliente sean identificadas como duplicados.

✅ Coincidencia ajustada (90-95%): Proporciona resultados óptimos con menos falsos positivos. Se establece un umbral de coincidencia ajustado para garantizar alta precisión en la identificación de duplicados. Por ejemplo, un umbral del 95% significa que solo las entradas con atributos muy similares (por ejemplo, «John Smith» y «Johnathan Smith») serán consideradas como coincidencias. Esto reduce el riesgo de falsos positivos, pero puede omitir algunas coincidencias potenciales.

Coincidencia flexible (80-85%): Aumenta la probabilidad de falsos positivos, pero puede capturar más coincidencias potenciales. Un umbral de coincidencia flexible permite más variabilidad en los criterios de coincidencia. Por ejemplo, un umbral del 85% podría identificar «J. Smith» y «Jon Smith» como coincidencias. Este enfoque puede capturar más duplicados posibles, pero también aumenta las posibilidades de falsos positivos, donde entradas no relacionadas se marcan incorrectamente como coincidencias.
Ejemplo de coincidencia ajustada: «Robert Brown» y «Bob Brown» podrían no coincidir con un umbral del 95%, pero «Robert Brown» y «Robert B.» sí lo harían.
Ejemplo de coincidencia flexible: «Robert Brown» y «Rob Brown» podrían coincidir con un umbral del 85%, capturando más duplicados potenciales, pero con un mayor riesgo de incluir falsos positivos.
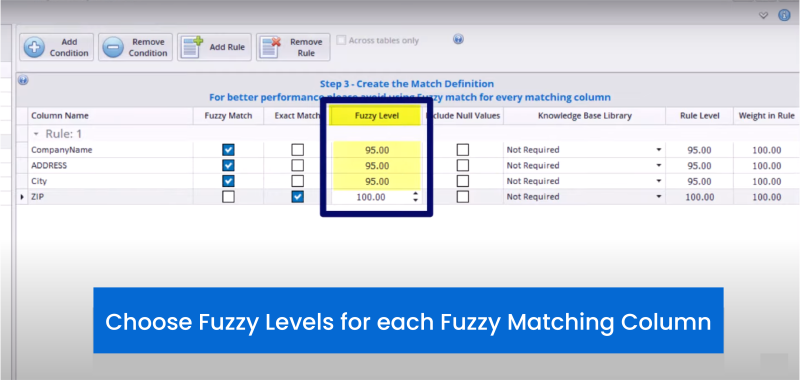
✅ Fusionar, sobrescribir, eliminar
Fusionar: Consolida la información redundante en un único registro integral. Por ejemplo, fusionar las direcciones «456 Elm Street» y «456 Elm St.» en un solo formato estandarizado.

✅Sobrescribir: Toma decisiones entre versiones conflictivas de los datos, como actualizar la Dirección B en lugar de la Dirección A. Por ejemplo, si un registro tiene una dirección desactualizada, la dirección correcta y actualizada puede sobrescribir la antigua.

Una solución de coincidencia difusa como WinPure permite al usuario crear bibliotecas personalizadas de palabras para evitar un falso positivo. Además, los usuarios pueden realizar coincidencias tantas veces como deseen sin corromper los datos.
¿Ves qué fácil fue?
Resolver un problema como este usando métodos manuales o codificación requiere pasos adicionales que no garantizan precisión. Además, afecta la eficiencia. ¡Tu equipo está perdiendo tiempo en problemas redundantes!
¿Cuánto tiempo y dinero puedes ahorrar con una herramienta de coincidencia difusa automatizada?
La mayoría de los líderes aún prefieren que sus equipos tecnológicos utilicen métodos manuales (como Python y SQL) para coincidir datos, lo que eventualmente les cuesta miles de dólares en tiempo de recursos y esfuerzo. A un analista le llevaría meses limpiar manualmente y luego hacer coincidir datos complicados, en comparación con una herramienta de coincidencia difusa automatizada que puede lograr los mismos resultados en minutos, sin comprometer la precisión, exactitud y control.
Aquí tienes una visión general de cuánto tiempo y dinero pueden ahorrar las empresas con una herramienta de coincidencia de datos. El cálculo se basa en un conjunto de datos típico de 50,000 registros, suponiendo que la coincidencia manual tomaría 100 horas a una tarifa de $25 por hora, frente a 1-2 horas y ~$300 usando una herramienta automatizada.
| Metric | Manual process | Automation | Expected savings |
| Time Spent (hours) | 100 | 2 | 98% time saved |
| Cost (USD) | $2,500 | $300 | 80% cost saved (~$2,000) |
| Effort Reduction | High (repetitive tasks) | Low (mostly review) | Significant (focus on high-value tasks) |
No solo estás ahorrando dinero, sino que también estás asegurando que tus equipos operen con eficiencia, ahorrando tiempo para tareas que realmente importan (como estrategia, gobernanza, prevención de errores, mantenimiento de datos, gestión de pipeline y muchas otras funciones que requieren tiempo valioso).
Ve cómo HDL generó £1M en ingresos usando la herramienta de coincidencia difusa de WinPure
HDL, una empresa líder en finanzas con más de 700 socios y agencias gubernamentales en EE. UU., ha recuperado más de $3 mil millones en ingresos para sus clientes. Para aumentar la eficiencia, HDL integró la API de coincidencia difusa de WinPure en su gestión de flujo de trabajo, utilizándola para limpiar, eliminar duplicados y consolidar los datos de los clientes. ¡En solo unos meses de gestión de datos optimizada, HDL logró un impresionante millón de libras adicionales en ingresos!
Descubre la historia completa: descarga el estudio de caso y ve cómo HDL transformó sus procesos de datos para lograr resultados extraordinarios.

¿Cómo mejora la coincidencia difusa los procesos empresariales?
Respondamos a esta pregunta con un escenario:
Imagina: Un equipo de marketing necesita preparar los informes de fin de año, pero sus datos están llenos de errores tipográficos, identificaciones duplicadas e información faltante. O un equipo de ventas está intentando crear informes y predicciones basadas en datos de ventas que están corruptos, tienen valores faltantes y una gran cantidad de problemas de calidad de datos.
Resolver estos desafíos lleva tiempo y esfuerzo, y ciertamente no pueden resolverse con métodos tradicionales.
Considera la coincidencia difusa como la ciencia detrás de la mayoría de los métodos de comparación de listas. Es la tecnología que hace posible la calidad de datos para la mayoría de las empresas. Además, también les ayuda a lograr objetivos críticos para el negocio como:
✅ Iniciativas impulsadas por IA: Los algoritmos de IA dependen de datos de alta calidad, y hasta las ligeras variaciones o duplicados en nombres, direcciones o detalles de contacto pueden llevar a perfiles fragmentados y predicciones sesgadas. Al unificar puntos de datos similares pero no exactos, la coincidencia difusa ayuda a crear conjuntos de datos más limpios, lo que permite que los modelos de IA comprendan mejor el comportamiento, las preferencias y los patrones de los clientes.
✅ Gestión de datos más fácil: En lugar de ordenar manualmente variaciones en nombres, direcciones o números de teléfono, los algoritmos de coincidencia difusa detectan y unifican estas inconsistencias, creando un único registro preciso para cada entidad. Este enfoque optimizado reduce la redundancia de datos, minimiza los requisitos de almacenamiento y hace que la actualización y el mantenimiento de los datos sean mucho más eficientes.
✅ Mejora de la eficiencia y colaboración: Con los equipos de TI y de negocio siempre luchando con la precisión de las listas de datos, una poderosa solución de coincidencia difusa como WinPure puede ayudar a agilizar el proceso de calidad de datos y reducir la dependencia de tareas manuales de coincidencia de datos.
✅ Visión 360 del cliente: La coincidencia de datos difusa permite una vista completa y unificada de cada cliente al fusionar registros con ligeras variaciones en nombres, direcciones u otros detalles. Esta vista integral ayuda a los equipos de negocio a comprender el historial del cliente, sus preferencias e interacciones a través de diferentes puntos de contacto, lo que lleva a una toma de decisiones más informada.
Y mucho más. La coincidencia de datos difusa no es solo una tecnología de TI: es, en gran parte, la ciencia que impulsa la mayoría de las plataformas de calidad de datos que están permitiendo a los equipos de negocio y tecnología convertir sus datos en una fuente confiable.
Para concluir: ¡La coincidencia de datos difusa es la columna vertebral de la calidad de los datos!
La coincidencia de datos difusa no es un concepto nuevo, sin embargo, ha ganado popularidad en los últimos años a medida que las organizaciones luchan con las limitaciones de los métodos tradicionales de eliminación de duplicados. Con una solución automatizada como WinPure, puedes ahorrar cientos de horas en esfuerzo manual y resolver duplicados con un nivel de precisión mucho mayor sin tener que preocuparte por crear algoritmos de código interno o contratar expertos costosos en coincidencia difusa.
Preguntas Frecuentes sobre la Coincidencia Difusa
- ¿Cuál es la diferencia entre coincidencia exacta y coincidencia difusa?
Una coincidencia exacta requiere que los campos de datos sean idénticos, como coincidir «John Smith» con «John Smith» sin variaciones. La coincidencia difusa, por otro lado, permite coincidencias cercanas pero no idénticas, como reconocer «Jon Smith» y «John Smith» como la misma persona. Esto hace que la coincidencia difusa sea más efectiva en situaciones donde los datos puedan contener errores tipográficos, ortografías alternativas u otras pequeñas discrepancias.
- ¿Por qué es importante la coincidencia difusa de datos para gestionar registros duplicados?
La coincidencia difusa de datos es crucial para gestionar registros duplicados porque puede identificar y fusionar registros que son similares pero no duplicados exactos. Por ejemplo, podría reconocer «Jonathan Doe» y «Jon Doe» como la misma persona, aunque sus nombres no sean exactamente iguales. Este proceso ayuda a garantizar que cada persona o entidad tenga un único registro unificado, reduciendo el desorden de datos y mejorando la calidad de los datos.
- ¿Se puede hacer coincidencia difusa en Excel?
Sí, puedes realizar coincidencia difusa en Excel, aunque requiere algunos pasos adicionales. Excel tiene un complemento llamado «Fuzzy Lookup» que te permite hacer coincidir registros similares pero no idénticos. Aunque este complemento ofrece capacidades básicas de coincidencia difusa, puede no ser tan potente o flexible como las herramientas dedicadas de coincidencia de datos, especialmente cuando se trabaja con grandes conjuntos de datos o requisitos complejos de coincidencia de datos.
- ¿Qué es la coincidencia difusa de datos sin código?
La coincidencia difusa de datos sin código se refiere a herramientas o plataformas que permiten a los usuarios realizar coincidencia difusa sin necesidad de habilidades de programación. Estas herramientas proporcionan interfaces fáciles de usar donde puedes configurar reglas de coincidencia, establecer umbrales de similitud y procesar datos con funcionalidad de arrastrar y soltar. Este enfoque es ideal para usuarios de negocios y analistas que necesitan limpiar y estandarizar datos sin escribir código.
- ¿Necesito aprender SQL para la coincidencia difusa de datos?
No, aprender SQL no es esencial para la coincidencia difusa de datos, aunque puede ser útil si trabajas con bases de datos estructuradas. Muchas herramientas sin código y de bajo código ofrecen funciones de coincidencia difusa que no requieren conocimientos de SQL. Sin embargo, si trabajas en entornos basados en SQL o deseas realizar coincidencias personalizadas directamente en bases de datos, conocer SQL puede brindarte más control y flexibilidad.
- ¿Cuáles son los beneficios de usar una herramienta de coincidencia difusa de datos?
Usar una herramienta de coincidencia difusa de datos ofrece múltiples beneficios, incluyendo una limpieza de datos más rápida, mayor precisión de los datos y reducción del trabajo manual. Estas herramientas están diseñadas para manejar diversas inconsistencias en nombres, direcciones y otros campos, creando registros unificados y ahorrando tiempo. Las herramientas de coincidencia difusa también mejoran la gestión de datos, lo que permite un mejor reporte, análisis y toma de decisiones al garantizar la calidad de los datos en los sistemas.
- ¿Cuáles son los errores comunes a evitar al realizar un proceso de coincidencia difusa?
Los errores comunes en el proceso de coincidencia difusa incluyen no limpiar ni estandarizar los datos de antemano, lo que puede llevar a coincidencias inexactas debido a formatos inconsistentes. Establecer umbrales de similitud demasiado amplios o estrechos es otro error común: un umbral demasiado bajo puede resultar en demasiadas coincidencias erróneas, mientras que un umbral demasiado alto puede hacer que se pierdan coincidencias válidas. Ignorar la coincidencia de múltiples campos, como combinar nombres con direcciones o fechas de nacimiento, también puede reducir la precisión, ya que hacer coincidencias solo en un campo a menudo lleva a falsos positivos. Además, depender únicamente de la configuración predeterminada de los algoritmos sin personalización, o pasar por alto la necesidad de una revisión manual, especialmente en conjuntos de datos complejos, puede comprometer la efectividad del proceso de coincidencia difusa. Abordar adecuadamente estos factores mejora tanto la calidad como la fiabilidad de los resultados de la coincidencia difusa.
Start Your 30-Day Trial!
Secure desktop tool.
No credit card required.
- Match & deduplicate records
- Clean and standardize data
- Use Entity AI deduplication
- View data patterns
... and much more!



